26 kwietnia 2024
Data & Analytics – architektura systemów jutra
Podczas konferencji „Transformacje cyfrowe dla biznesu” opowiedzieliśmy o trendach w architekturze systemów z obszaru Data & Analytics, na które warto zwrócić szczególną uwagę. Postaramy się pogłębić ten temat i przybliżyć kilka nowoczesnych rozwiązań. A zaczniemy od omówienia historii inżynierii danych i znajdziemy swoje miejsce na osi czasu.
Krótka historia inżynierii danych
Omówienie architektury systemów jutra zacznijmy od szybkiego przypomnienia gdzie, w świecie Data & Analytics jesteśmy dzisiaj i gdzie byliśmy wczoraj. Na szczęście historia współczesnej inżynierii danych nie jest długa. Proponujemy wyróżnić 4 ery.

Era Megabajta – końcówka XX wieku
Historia ta zaczyna się już w latach 80. ubiegłego wieku, w czasach, które możemy nazwać Erą Megabajta.
W Erze Megabajta:
- pojawiła się możliwości elektronicznego zapisu danych (w ustrukturyzowanej formie, czyli w tabelach)
- powstały pierwsze elektroniczne arkusze kalkulacyjne, w których za pomocą klawiatury i myszki człowiek zaczął wchodzić w interakcję z danymi
- powstały również bazy danych i język strukturalnych zapytań SQL
Era Terabajta – początek XXI wieku
Przez kolejne 20 lat technologia strukturalna rozwijała się, danych przybywało, z Mega przeszliśmy do Tera. Powstawały kolejne modele relacyjne, takie jak schemat gwiazdy, szeroko wykorzystywane w nowym rodzaju repozytorium danych, zwanych magazynem. Jego głównym zadaniem jest zbieranie i analizowanie olbrzymich ilości danych.
W Erze Terabajta:
- pierwszy raz użyto sformułowania Big Data
- powstały narzędzia rozproszonego przetwarzania danych w tzw. klastrach (czyli grupach maszyn)
- Internet stał się ogólnodostępny i powstały pierwsze chmury obliczeniowe
Era Petabajta – druga dekada XXI wieku
W kolejnej dekadzie przede wszystkim przybywało danych (do tej pory niespotykanych na masową skalę) – nagrań wideo i audio, zdjęć, danych tekstowych i wiele innych – a mnóstwo z nich generowanych było przez ludzi korzystających z prężnie rozwijających się serwisów społecznościowych. Wzrost już nie był liniowy, lecz wykładniczy.
W Erze Petabajta:
- popularność zdobyły źródła danych niestrukturalnych
(czyli tekstów, obrazów, filmów, generalnie wszystkiego oprócz tabel) - wprowadzono nową technologię: jezioro danych (ang. Data Lake) do zbierania i analizowania niestrukturalnych danych
- powstało Onwelo (2015) 😊
Era Zettabajta
Wykładniczy wzrost ilości danych spowodował wkroczenie w Erę Zettabajta – erę, w której nie tylko człowiek generuje dane – pojawia się nowe źródło danych: sztuczna inteligencja.
Ciekawostka:
1 zettabajt to 10 do 21 potęgi bajtów. To tak niewyobrażalnie dużo, że gdyby wydrukować 1 zettabajt danych w książkach i ustawić je w wieżę, to moglibyśmy się po niej wspiąć np. do najbliższej sąsiedniej Galaktyki Andromedy… 7 razy.
Na szczęście dane, w przeciwieństwie do książek, można kompresować i zapisywać w sprytny sposób.
W Erze Zettabajta:
- wprowadzono technologię Delta Lake umożliwiającą traktowanie nieustrukturyzowanych danych zgromadzonych w Lake’ach tak samo jak dane strukturalne w bazie i odpytywać za pomocą SQL-a
- olbrzymi nacisk kładziono na zwiększanie poziomu abstrakcji i automatyzacji, czyli upraszczanie żmudnych czynności przez gotowe rozwiązania
- zebrano wystarczająco dużo zbiorów danych i mocy obliczeniowej, aby trenować olbrzymie modele sztucznej inteligencji, zawierające miliardy parametrów, dzięki czemu generatywna sztuczna inteligencja stała się szeroko dostępna
Teraźniejszość 2023/2024
Statystyki – co się obecnie dzieje w Data & Analytics?
Przeszłość już za nami – spójrzmy na garść statystyk z 2023 roku.
- Większość, bo aż 65% europejskich firm postrzega umiejętności cyfrowe jako kluczowe dla codziennej działalności
- Ale tylko 1 na 5 Europejczyków dobrze zna pojęcie chmury obliczeniowej
- Coraz więcej europejskich firm używa chmury w swojej działalności. W 2023 roku było to 30%, o 15 punktów procentowych więcej niż w roku 2022. Nastąpił aż dwukrotny wzrost!
- Niestety prawie połowa europejskich firm ma problem z pozyskiwaniem nowych pracowników o pożądanych umiejętnościach cyfrowych
Źródło informacji: Unlocking Poland’s AI Ambitions in the Digital Decade | AWS Poland
Unistore – nasza odpowiedź na aktualne trendy
Na szczęście w Onwelo mamy wielu specjalistów chmurowych i wychodzimy naprzeciw aktualnym potrzebom. Nasz produkt Unistore, gromadzący wszystkie dane w jednym miejscu, został zaprojektowany z jednym głównym celem: pomóc klientom w osiąganiu mierzalnych korzyści biznesowych, czyli np. zwiększanie obrotów, obniżenie ryzyka, zwiększenie wydajności i jakości.
Unistore zapewnia osiągnięcie tego celu dzięki wykorzystaniu 4 głównych modułów.

- Moduł efektywnego magazynowania danych, bezpiecznej i automatycznej archiwizacji –
pozwala zmniejszyć wydatki dzięki dostosowywaniu optymalnego rodzaju przechowywania danych - Moduł automatycznego oczyszczania i zgłaszania nieprawidłowości danych – działając już na etapie ingestion pozwala oszczędzić czas dzięki gwarancji poprawności danych
- Moduł zoptymalizowanego transformowania danych – pozwala wydajnie pozyskiwać informacje zawarte w danych wejściowych
- Moduł wygodnej prezentacji – przedstawia informacje w przystępny sposób, wspierając analitykę biznesową
Przyszłość – architektura systemów jutra
Skupimy się na trendach, które, naszym zdaniem, należy szczególnie wziąć pod uwagę przy projektowaniu systemów inteligencji biznesowej.
Delta Lake do gromadzenia danych
Jednym z wiodących trendów w budowaniu nowoczesnych platform analitycznych jest zastosowanie optymalnej formy zapisu danych. Pierwotnie dane zapisywano bezpośrednio w bazach danych na serwerach SQL. Każdy serwer miał określoną nieprzekraczalną pojemność. Za każdym razem, gdy ilość danych przekraczała pojemność serwera, trzeba było robić czasochłonną migrację i wyłączać środowisko produkcyjne. Następnie wprowadzono hurtownie danych, które łączyły w jednym środowisku wiele baz danych, dzięki czemu w lepszy sposób były przygotowane do integracji większej ilości danych pochodzących z różnych źródeł. Pojawienie się rozwiązania Data Lake było prawdziwym przełomem w budowaniu platform analitycznych, gdyż od tego momentu można odseparować storage od computing (mocy obliczeniowej).
Popularnym formatem zapisu danych stał się Parquet, który jako columnar data store oszczędza nawet 10-krotnie miejsce potrzebne do zapisania danych niż pliki płaskie typu CSV, ponadto umożliwia prawie 34-krotnie szybsze odpytywanie danych. Kluczowymi ograniczeniami zapisu danych w postaci Parquet są: brak możliwości ładowania i modyfikowania danych w sposób inkrementalny oraz wyzwania związane z konkurencyjnością (np. brak możliwości jednoczesnego zapisu i odczytu danych). Na te wyzwania odpowiedziała Delta. Dane wówczas zapisywane są w formie folderu, który jest kombinacją logów i plików Parquet. Deltę można traktować prawie tak samo jak odrębną instancję bazy danych. Można dodawać do niej nowe wiersze, modyfikować istniejące oraz usuwać niepotrzebne. Delta Lake ponadto w pełni wspiera ACID transakcje, dzięki którym mamy gwarancję poprawnego przetwarzania danych zapewniającego spójność, niepodzielność, izolację i trwałość.
W oparciu o Deltę powstało pojęcie Delta Lakehouse, czyli platformy, która zapisuje dane na storage’u w postaci magazynu Delta Lake oraz umożliwia ich odczytywanie prawie w taki sam sposób jak relacyjną bazę danych. W nowoczesnych serwerlessowych platformach analitycznych dostawcy technologii cloud coraz częściej oferują uproszczoną formę rozliczania się za odpytywanie magazynu Delta Lake, stosując single price model (SKU).
Technologia Delta Lake została również mocno zaadoptowana na potrzeby użytkowników platform do wizualizacji danych poprzez Direct Lake. Direct Lake to nowatorska funkcja analizowania bardzo dużych ilości danych zastosowana w Power BI.
Platformy niskokodowe (low-code) i SaaS

Kierunkiem rozwoju analitycznych platform danych jest wykorzystywanie podejścia typu low-code.
Low-code to technika programowania wykorzystująca małą ilość kodu. Dzięki wykorzystaniu mechanizmu drag & drop platformy analityczne typu low-code umożliwiają wizualne tworzenie aplikacji bez konieczności posiadania zaawansowanej wiedzy z zakresu języków oprogramowania. Według raportu Gartnera (Gartner and McKenzie’s approach to data-driven enterprises in 2024 – Conciliac EDM) do końca 2024 roku 75% dużych przedsiębiorstw będzie korzystać z platform typu low-code. Korzyści z zastosowania low-code to większy dostęp do narzędzi służących do obróbki i przygotowania danych w ramach projektu oraz większa łatwość w utrzymaniu skomplikowanych procesów przetwarzania danych. Low-code to także zmniejszenie kosztów tworzenia i, co za tym idzie, czasu tworzenia aplikacji. To właśnie dzięki low-code analitycy i deweloperzy w łatwiejszy sposób mogą korzystać z bardziej zaawansowanych rozwiązań, które teraz są dostępne na wyciągnięcie ręki.
Platformy analityczne klasy Software as a Service (SaaS) w znaczny sposób zwiększają podstawowy parametr wszystkich projektów software’owych czyli: Time to Value. Dzięki korzystaniu z prekonfigurowanych usług i środowiska oraz przerzucenia odpowiedzialności na dostawcę możemy skupić się w większym stopniu na budowaniu biznesowej wartości dodanej naszego serwisu. Platformy SaaS to także rozwiązania serwerlessowe, w ramach których płacimy za realne zużyte moce obliczeniowe lub konkretną wielkość storage’u.
Demokratyzacja danych
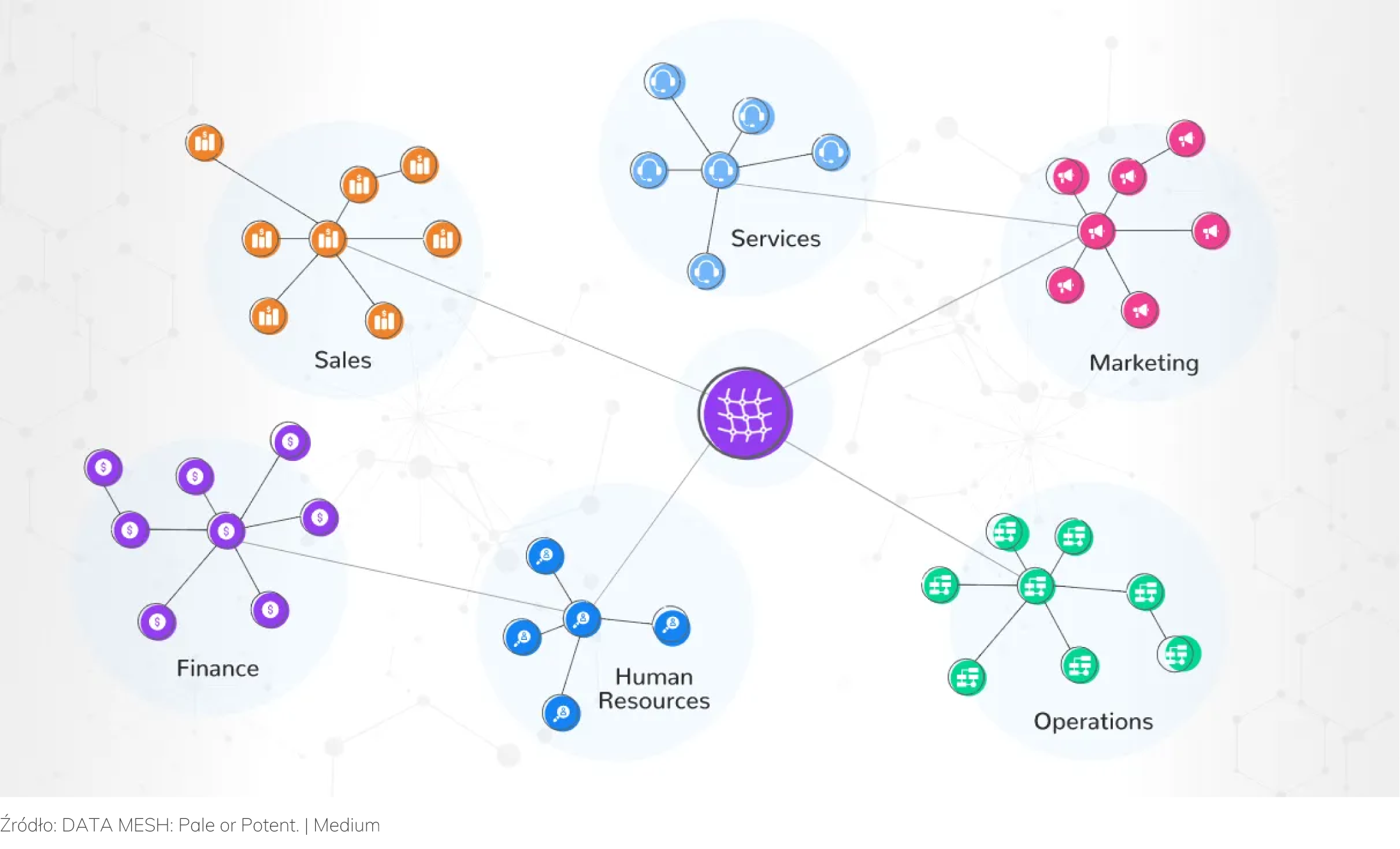
Wzmocnienie pozycji i poprawa jakości pracy zespołów projektowych poprzez dostęp do aktualnych, spójnych i zintegrowanych danych są w obecnych czasach bardzo istotne. W wielu projektach lub organizacjach o scentralizowanej strukturze dostęp do danych jest nadawany bardzo wąskiej grupie użytkowników. Gdy ktoś spoza tej grupy chce je zdobyć, musi często przejść bardzo długi proces weryfikacji, aby otrzymać jednorazowy dostęp do danych. Jeżeli dodamy do tego czas potrzebny na transformację danych w celu wyliczenia odpowiedniego KPI (Key Performance Indicators), to cały proces podejmowania właściwych decyzji biznesowych na podstawie analizy danych traci mocno na jakości.
Danych w projektach jest coraz więcej, otrzymujemy je coraz szybciej, a metody ich modelowania coraz bardziej są domeną analityków biznesowych lub osób o mniejszych kompetencjach technicznych. Aby wyjść naprzeciw oczekiwaniom, coraz częściej w organizacjach stosuje się politykę demokratyzacji danych. Dane udostępniane są wraz z narzędziami służącymi do pracy z nimi różnym zespołom. Odchodzi się już od tradycyjnego podziału osób pracujących z danymi na analityków i inżynierów danych. Teraz tworzy się zespoły osób skupionych w obrębie określonej domeny projektu lub organizacji (np. marketing, sprzedaż czy finanse). Uczestnicy takiego zespołu mając dużo większą wiedzę o naturze analizowanych danych, dopasowują procesy ich przetwarzania i wizualizacji do własnych potrzeb i tworzą skrojone pod siebie data produkty. Dzięki zastosowaniu tego podejścia organizacja w znacznie lepszy sposób jest w stanie skorzystać z potencjału danych i podejmować dzięki nim lepsze decyzje biznesowe.
Podsumowanie
Cztery ery historii inżynierii danych, od możliwości elektronicznego zapisu danych do technologii sztucznej inteligencji. Od lat 80., kiedy pojawiła się pierwsza możliwość interakcji z danymi drogą komputerową do dzisiaj, kiedy umiejętności cyfrowe są uważane za powszechne. Technologia Delta Lake będąca przełomem w formie zapisu danych, podejście low-code umożliwiające tworzenie aplikacji bez konieczności posiadania zaawansowanej wiedzy, sprawne korzystanie z danych w organizacjach dzięki podejściu demokratyzacji danych – na te trendy rynkowe warto zwrócić szczególną uwagę i podążać za zmieniającymi się technologiami, zachowując wysoką efektywność biznesową i konkurencyjność.
Marek Kozioł – Data Solution Architect w Onwelo, a wcześniej Business Development Manager z 18-letnim doświadczeniem w branży IT. Prywatnie gra w baseball i ćwiczy crossfit.
Arkadiusz Zdanowski – Cloud Data Engineer & Team Leader w Onwelo. Od 2 lat realizuje projekty modernizujące technologie bazodanowe, głównie migracje do chmury.
Konferencja „Transformacje cyfrowe dla biznesu” zorganizowana przez Onwelo odbyła się 27 marca 2024 r. w warszawskim budynku Skyliner. Wydarzenie poświęcone było sztucznej inteligencji, rozwiązaniom cloud oraz ochronie zasobów IT w procesach transformacji cyfrowych dla firm. Była to okazja do spotkania się w gronie naszych partnerów biznesowych, przedstawicieli dynamicznie działających firm z różnych branż, nastawionych na rozwój technologiczny. Dziękujemy wszystkim uczestnikom! W kolejnych artykułach będziemy przybliżać tematy prezentowane podczas konferencji.
Zostaw komentarz
Polecamy

Sztuczna inteligencja w wykrywaniu zagrożeń bezpieczeństwa IT
Cyberbezpieczeństwo to nie tylko zaawansowane technicznie systemy zabezpieczeń w dużych firmach czy wojsku. To także nasze prywatne bezpieczeństwo, walka z zagrożeniami i ich prewencja w codziennym życiu oraz wiedza o bezpiecznym korzystaniu z internetu. Adam Kowalski-Potok, nasz Seurity Engineer, opowiada jak AI i jej rozwój wpływa na wykrywanie zagrożeń w cyber security.

Budowanie systemów biznesowych z zastosowaniem generatywnej sztucznej inteligencji
Generatywne AI ma potencjał do automatyzacji zadań zajmujących dziś do 70% czasu pracowników. Dlaczego platforma OpenAI nie wystarczy do wykorzystania pełni tych możliwości? Przed nami artykuł Łukasza Cesarskiego i Marka Karwowskiego z Onwelo powstały na bazie prezentacji wygłoszonej podczas konferencji „Transformacje cyfrowe dla biznesu”.

Kompleksowa realizacja infrastruktury cloud przy użyciu praktyk DevOps
Transformacja cyfrowa dla biznesu to zmiana sposobu myślenia o zarządzaniu i rozwijaniu systemów IT. Zapraszamy do lektury artykułu Pawła Kalarusa i Sebastiana Frankiewicza, którzy szerzej opisują temat zaprezentowany podczas marcowej konferencji Onwelo.
Sztuczna inteligencja w wykrywaniu zagrożeń bezpieczeństwa IT
Cyberbezpieczeństwo to nie tylko zaawansowane technicznie systemy zabezpieczeń w dużych firmach czy wojsku. To także nasze prywatne bezpieczeństwo, walka z zagrożeniami i ich prewencja w codziennym życiu oraz wiedza o bezpiecznym korzystaniu z internetu. Adam Kowalski-Potok, nasz Seurity Engineer, opowiada jak AI i jej rozwój wpływa na wykrywanie zagrożeń w cyber security.
Budowanie systemów biznesowych z zastosowaniem generatywnej sztucznej inteligencji
Generatywne AI ma potencjał do automatyzacji zadań zajmujących dziś do 70% czasu pracowników. Dlaczego platforma OpenAI nie wystarczy do wykorzystania pełni tych możliwości? Przed nami artykuł Łukasza Cesarskiego i Marka Karwowskiego z Onwelo powstały na bazie prezentacji wygłoszonej podczas konferencji „Transformacje cyfrowe dla biznesu”.