W czasach cyfryzacji coraz więcej czynności wykonywanych przez człowieka może być realizowanych automatycznie. Przykładem niech będzie sporządzenie raportu. Napisanie skryptu, który wykona za nas żmudną pracę, jest stosunkowo proste, jednak aby automatyzacja była pełna, skrypt musi się uruchomić bez udziału człowieka. Rolę osoby uruchamiającej skrypt pełni narzędzie działające bez przerwy, które w wyznaczonym dniu, o wyznaczonej godzinie aktywuje pożądaną akcję. Takim narzędziem może być Apache Airflow.
Czym jest Airflow?
Zatem od początku. Czym jest Airflow? Jak możemy przeczytać na stronie zawierającej dokumentację:
„Apache Airflow to platforma typu open source do tworzenia, planowania i monitorowania przepływów pracy zorientowanych wsadowo. Rozszerzalny framework Python Airflow umożliwia tworzenie przepływów pracy łączących się z praktycznie dowolną technologią. Interfejs sieciowy pomaga zarządzać stanem przepływów pracy. Airflow można wdrożyć na wiele sposobów, od pojedynczego procesu na laptopie po rozproszoną konfigurację do obsługi nawet największych przepływów pracy”.
Jak więc widać, z pomocą Airflow można tworzyć i zarządzać pracą – procesami, w ramach których wykonywane są poszczególne zadania. Jest to narzędzie typu open source, więc jego użycie w projekcie nie jest obarczone koniecznością zakupu licencji. Charakterystyczne dla Airflow jest to, że workflow jest definiowany w kodzie Pythonowym. Choć z pozoru może się to wydawać skomplikowane, pracochłonne i trudne, tak naprawdę jest dość wygodne i dla kogoś, kto zna Pythona – stosunkowo proste. Narzędzie to jest dość elastyczne, można je w łatwy sposób dostosowywać do wymagań projektowych oraz technologicznych. Istnieje również opcja rozszerzenia i personalizacji opcji, z których korzystamy. Głównym konceptem wykorzystywanym w Airflow jest DAG czyli Direct Acycling Graph, który kolekcjonuje taski (funkcje lub inne operacje dostępne w platformie Airflow) wykonywane w ramach danego workflowu.
Poniżej przedstawiona jest graficzna interpretacja DAG-a.*
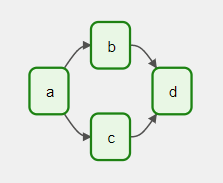
Zatem DAG kolekcjonuje taski (a, b, c, d) oraz przedstawia graficznie przepływ workflowu. Używając słowa kluczowego: „with DAG(…) as dag”, definiujemy, jak ma wyglądać workflow, a Airflow interpretuje tę definicję i pokazuje ją w formie grafu.
Może się to wydawać na początku nieco skomplikowane. Zobaczmy to na przykładzie.
Analiza kodu DAG-a
Przykład definicji DAG-a w kodzie Pythonowym.
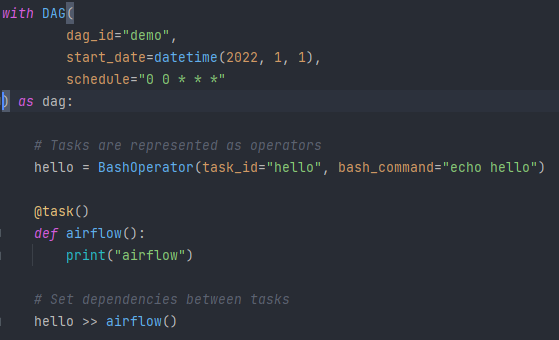
W pierwszej kolejności zajmijmy się blokiem kodu „with DAG(…) as dag:…”.
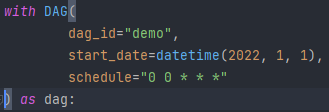
Tworzymy instancje DAG-a, do którego będziemy potem przypisywać taski i ustalać, jak ma wyglądać workflow.
Parametry:
- dag_id – jest to zarówno ID, jak również nazwa DAG-a, która będzie nam się wyświetlać w dashboardzie. ID musi być unikatowe dla każdego DAG-a
- start_date – to parametr, który przyjmuje instancje klasy DateTime, na podstawie której określa, od jakiej daty DAG ma działać (jeżeli chcielibyśmy, aby DAG był aktywny, ale żeby pierwsze uruchomienie flow odbyło się za kilka dni od momentu jego (DAG-a) wrzucenia na środowisko, możemy określić, od jakiej daty ma on wystartować)
- schedule – parametr decydujący o tym, co jaki odstęp czasu workflow ma się wykonywać. Jest to ustawione za pomocą cron (dobra stronka do ustawiania cron to crontab guru). Ten konkretny zapis oznacza uruchomienie każdego dnia o godzinie 00:00
Innym wskaźnikiem niezaprezentowanym tutaj, ale wartym użycia, jest catchup. To parametr typu bool, domyślnie ustawiany na True. Warto ustawić go na False, zwłaszcza gdy start_date jest dość odległy (tak jak na przykład tutaj, ustawiony na początek zeszłego roku). Domyślnie z catchup na True, Airflow uruchomi DAG-a tyle razy, ile powinien mieć uruchomień od start_date do dnia dzisiejszego.
Dowiedzieliśmy się już, co robi pierwsza linijka, możemy więc pójść dalej, gdzie znajduje się definicja pierwszego taska.
hello jest taskiem typu BashOperator. Jest to operator Airflow, który wywołuje komendę bashową w cli. Przyjmuje (w tym przypadku) dwa parametry:
- task_id – nazwa i zarazem ID, które będzie mieć nasz task (nazwa również musi być unikatowa)
- bash_command – komenda bashowa, którą chcemy wywołać
Kolejny task zdefiniowany jest nieco inaczej. Jest to funkcja Pythonowa, z przypisanym dekoratorem task. Jest to jeden (nieco mniej pracochłonny) ze sposobów na zdefiniowanie taska, który wywołuje naszą customową funkcję Pythonową. Do definicji takiego taska można również użyć operatora PythonOperator. Wygląda to wówczas tak jak poniżej.
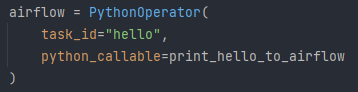
print_hello_to_airflow to zwykła funkcja Pythonowa zdefiniowana dokładnie w ten sam sposób jak funkcja airflow() (oprócz nazwy funkcji i dekoratora). Efekt jest ten sam, jednak metoda z dekoratorem częściej zaczęła się pojawiać w przykładach z dokumentacji w nowszych wersjach (wcześniej chociażby w wersji 2.2.2, w której pracowałem – tam również działała, jednak częściej napotykałem przykłady z PythonOperator). Próbując więc znaleźć rozwiązanie trapiącego nas problemu np. na forach, można spotkać obie wersje.
Poznaliśmy już dwa sposoby definicji tasków – jeden przeznaczony do funkcji Pythonowych, z użyciem dekoratora oraz klasyczny, z użyciem operatorów.
Operatorów w Airflow jest oczywiście znacznie więcej i można je znaleźć na stronie Apache Airflow.
Mamy już zatem stworzonego DAG-a i mamy zdefiniowane dwa taski. Należy te taski teraz odpowiednio ułożyć. O tym decyduje ostatnia linijka.

Najpierw wykonywany będzie task hello, a następnie airflow().
Wygenerowany przez Airflow graf wygląda tak jak poniżej.
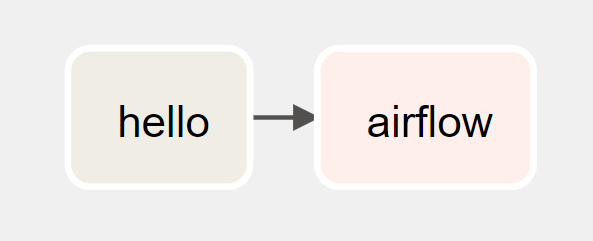
Gdybyśmy tego nie zrobili – nie ułożyli tego procesu, oczywiście DAG nadal by się stworzył, a nawet uruchomiłby się poprawnie i wykonał przebieg bez żadnych błędów. Bez ustawienia zależności między taskami graf wyglądałby tak jak poniżej.
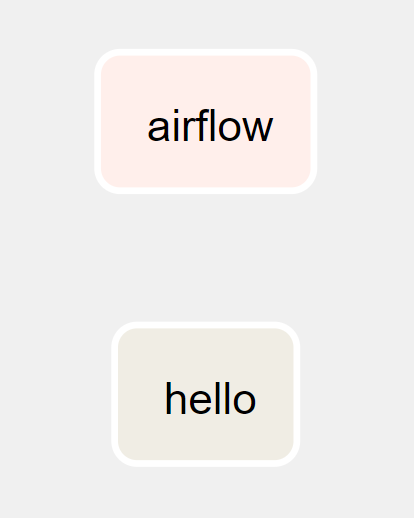
Byłyby to dwa niezależnie od siebie wykonujące się taski. Jeżeli nie ustawimy zależności między taskami, wykonają się one równolegle (rozpoczną swą pracę w chwili uruchomienia DAG-a). O ile w tym przykładzie ta zmiana nie ma większego znaczenia, to w standardowych zadaniach ETL-owych (Extract -> Transform -> Load) ma to ogromne znaczenie, gdyż tam kolejne kroki są ze sobą ściśle powiązane i muszą się wykonać w określonej kolejności.
Podsumowując, tak oto wygląda DAG z przykładu, który wyświetla w konsoli po prostu hello, a potem printuje airflow.
W następnej kolejności chciałbym opowiedzieć o tym, w jaki sposób można zarządzać DAG-ami oraz jak je uruchamiać, czyli powiemy sobie, gdzie znajduje się centrum dowodzenia.
Airflow udostępnia narzędzie – webserwer, gdzie mamy skolekcjonowane wszystkie DAG-i. W dużym skrócie jest to graficzny interfejs uruchamiany w przeglądarce, w którym można zarządzać DAG-ami, podglądać poprzednie uruchomienia oraz włączać je.
Strona główna webserwera wygląda tak jak poniżej.

Mamy tutaj wszystkie stworzone DAG-i, w tym DAG demo, na którego przykładzie opisana była składnia. Jak widać, DAG ma taką nazwę, jaka mu została nadana w parametrze dag_id. Kiedy klikniemy w niego, przejdziemy do poniższego widoku.
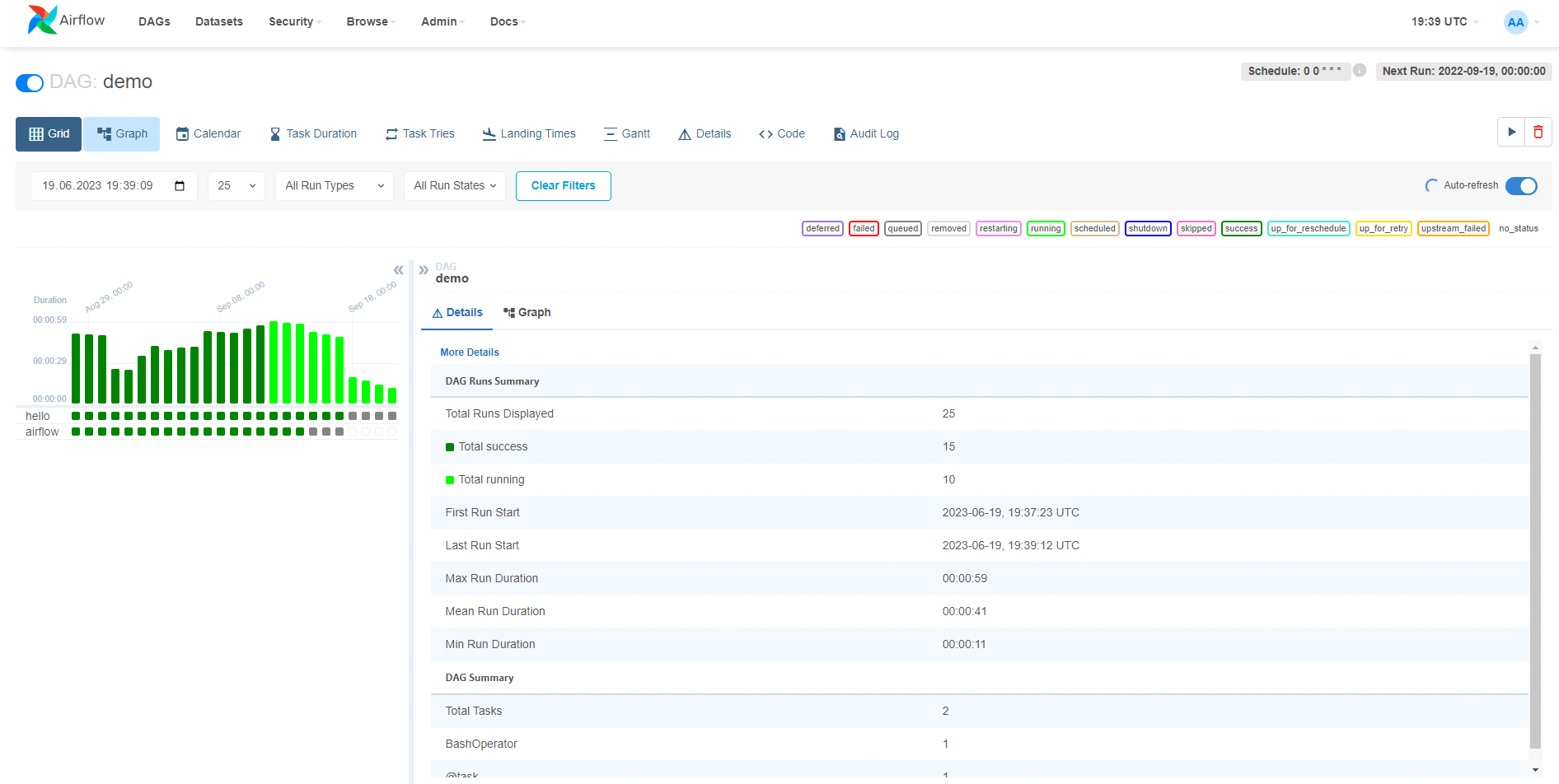
Mamy tutaj wiele informacji, ale przede wszystkim na wykresie słupkowym w lewym rogu widzimy poprzednie uruchomienia (kolor ciemnozielony) oraz aktualne uruchomienia (kolor jasnozielony). Pracując z Airflow, bardzo często będziemy korzystać z tego widoku, wracając do poprzednich uruchomień (zwłaszcza jeśli na przykład podczas weekendu zdarzy się wypadek na produkcji :)). Można tam podejrzeć wszystkie parametry, z jakimi został uruchomiony DAG oraz ewentualne logi z błędu, jeśli jakiś wystąpił. Dalej mamy zakładkę Graph, gdzie znajduje się wcześniej prezentowany graf workflowu.
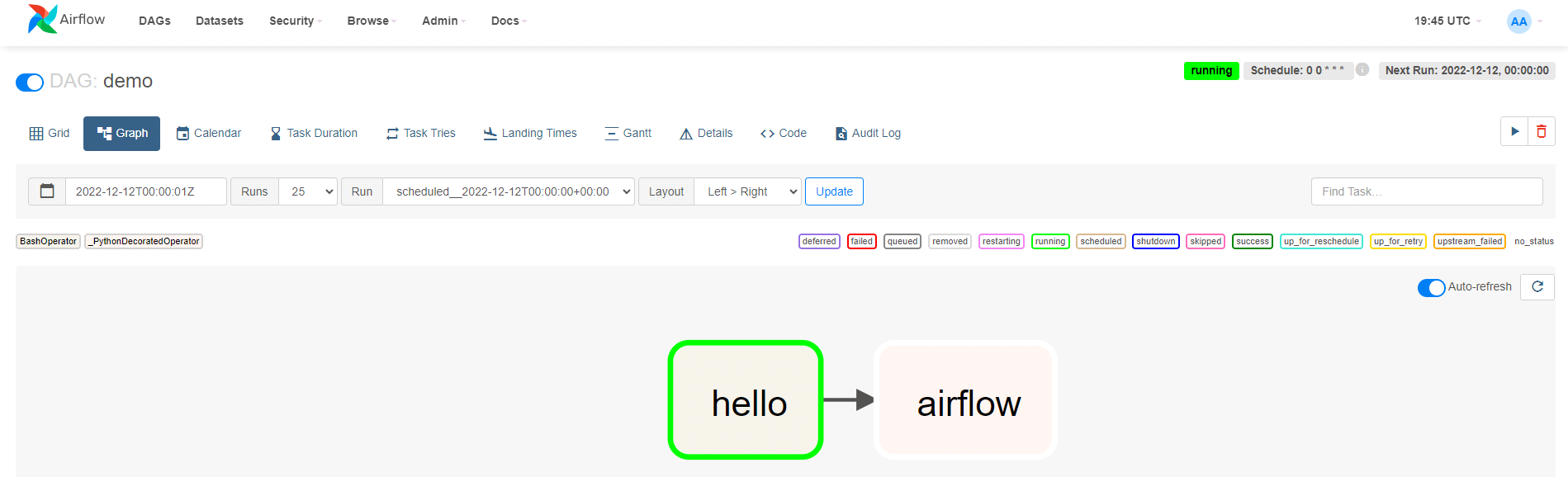
Widzimy tutaj dwa taski, hello i airflow, które uruchamiane są jeden po drugim. Jeśli klikniemy w dany task, ukażą nam się opcje umożliwiające podejrzenie logów z jego wykonania.
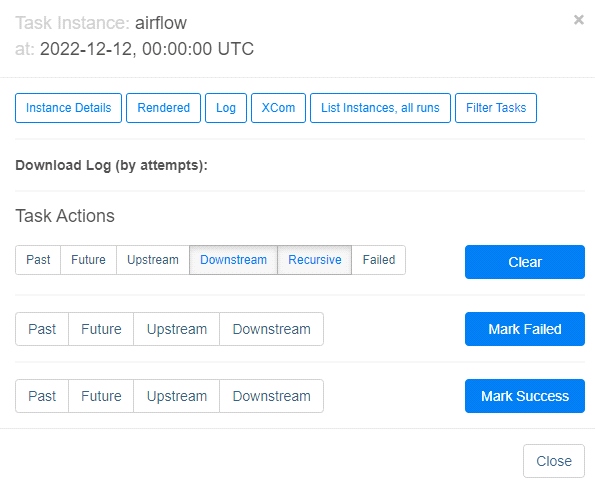
Poniżej widzimy logi z wykonania taska.
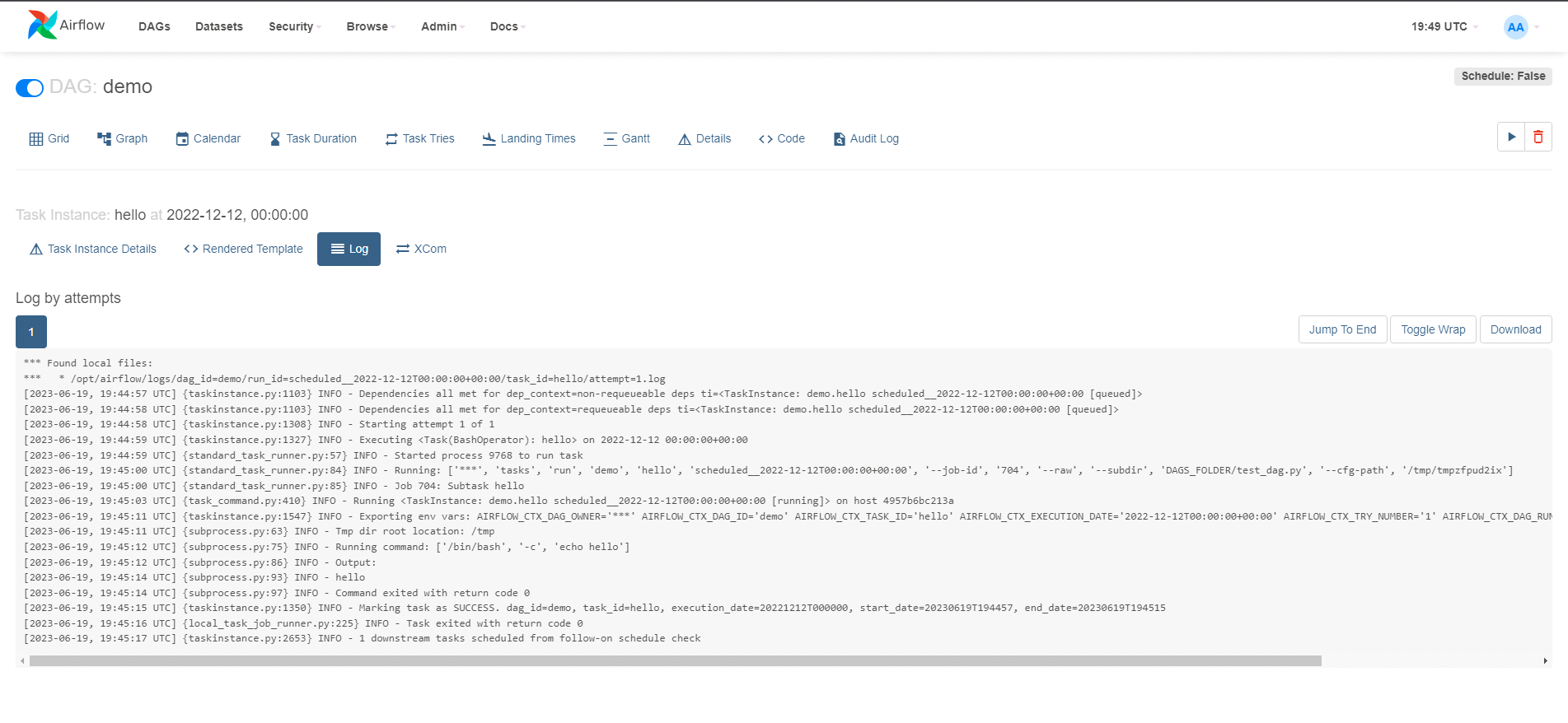
W logach widać efekt wywołania komendy bashowej {{ echo hello }}.

Kolejną bardzo przydatną zakładką jest Code. Kiedy przejdziemy do tej zakładki, będziemy mogli podejrzeć aktualny kod, który definiuje DAG-a.
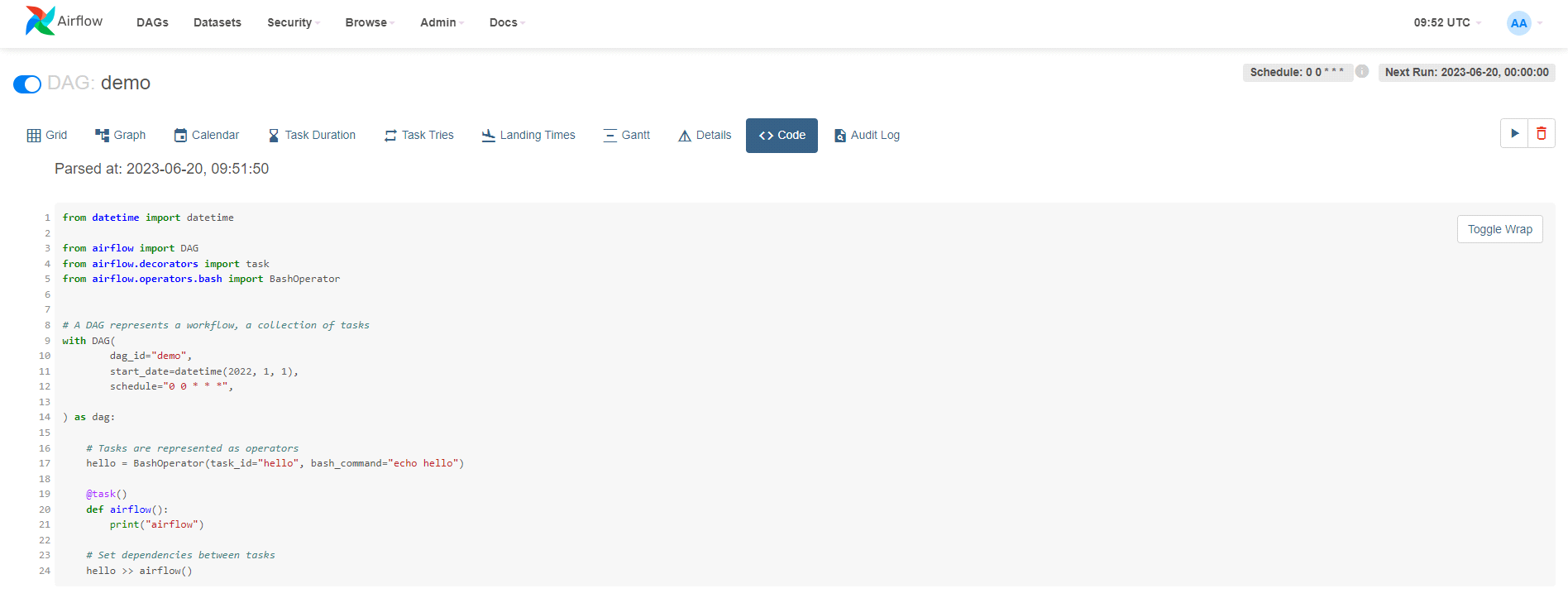
Można więc w łatwy sposób zweryfikować, czy najnowsze zmiany zostały już wgrane do środowiska.
Podsumowując – przeanalizowaliśmy działanie DAG-a, zobaczyliśmy, co robi, jak się go definiuje oraz jak można tworzyć taski. Jest to tylko jeden z przykładów użycia Airflow. Jest to narzędzie o potężnych możliwościach. Gdyby napisać o wszystkich jego zastosowaniach, powstałaby obszerna publikacja.
Skoro ścieżki zostały przetarte, nic nie stoi na przeszkodzie, aby samemu spróbować swoich sił!
Airflow na lokalnej maszynie
Jednym ze sposobów użycia tego narzędzia jest zainstalowanie go bezpośrednio na swoim komputerze. Polecam skorzystanie z Dockera, z kilku powodów. Jednym z nich jest fakt, że Airflow powinien być uruchamiany na Unixowym systemie, a większość z nas raczej ma Windowsa. Kolejnym powodem jest wygoda – w pliku docker-compose możemy zarządzać nie tylko wersją, ale także lokalnym adresem, przez który będziemy mogli wejść na webserver, czyli do naszej aplikacji webowej oraz skorzystać z wielu innych opcji, które będziemy mieć skondensowane w jednym pliku.
W załączniku do tego artykułu udostępniam plik docker-compose.yml, z którego korzystam przy uruchamianiu Airflowa na Dockerze. Wystarczy tylko uruchomić komendę docker compose up -d w docelowym katalogu (jeżeli mamy zainstalowanego Dockera) i Docker pobierze zdefiniowaną w pliku yaml wersję Airflowa oraz inne obrazy, które są potrzebne do poprawnego działania. Po wywołaniu wcześniej wspomnianej komendy Dockerowej i uruchomieniu obrazu aplikację webową znajdziemy pod tym adresem. Tutaj trzeba się wykazać chwilą cierpliwości. Mimo że webserwer będzie mieć już status running w Dockerze, aplikacja webowa nie będzie od razu dostępna. Trzeba dać serwerowi chwilę, żeby wszystko działało poprawnie. Zatem jeżeli po uruchomieniu docker-compose przez jakiś czas nie możemy wejść do aplikacji webowej pomimo tego, że webserwer już jest uruchomiony, należy chwilę poczekać, zanim zaczniemy się martwić, że coś nie działa.
Po wejściu do aplikacji webowej znajdziemy wiele przykładowych DAG-ów dostarczonych przez Airflow, które możemy uruchamiać, podglądać ich kod i poznawać różne funkcjonalności.
Jeżeli chcemy wrzucić swojego DAG-a, należy wrzucić plik Pythonowy do katalogu dags w miejscu, gdzie uruchomiliśmy docker-compose.
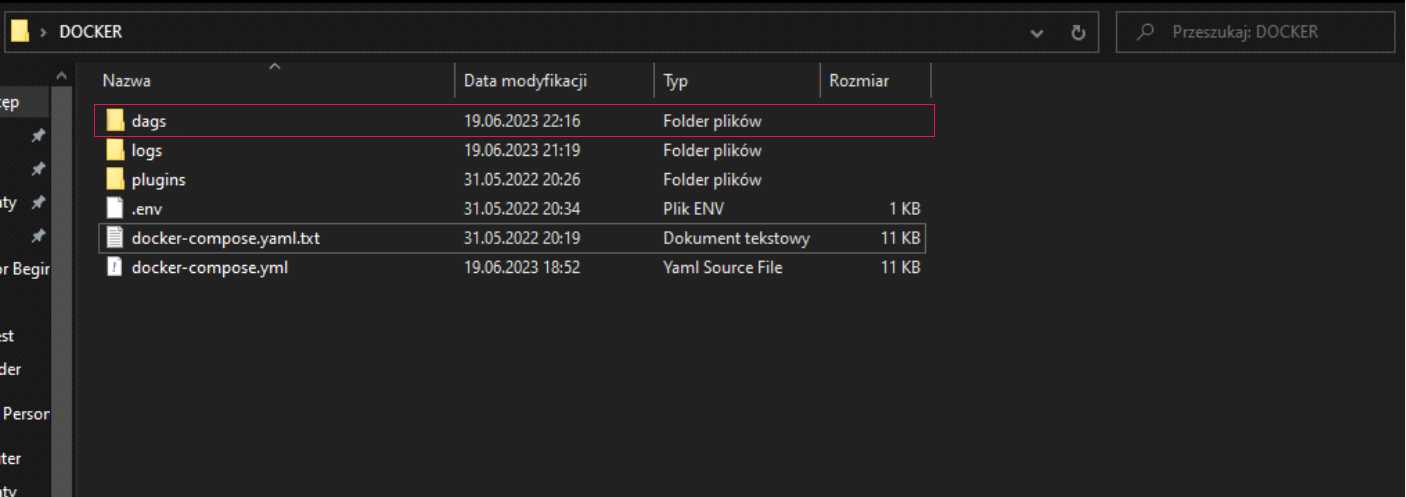
Zawartość katalogu wygląda tak jak poniżej.
Airflow sam zorientuje się, że został tam umieszczony nowy plik (nie od razu oczywiście, tutaj też trzeba dać mu chwilę : ) ) i po chwili ujrzymy na liście nowego DAG-a.
Jeżeli po dłuższej chwili nasz DAG nie pojawia się na liście, należy w pierwszej kolejności sprawdzić, czy aby nie użyliśmy dag_id już istniejącego DAG-a. W takiej sytuacji Airflow nie wyrzuci żadnego błędu, a jedynym objawem będzie brak nowego DAG-a na liście.
Airflow – kolejne kroki
Podsumowując – omówiliśmy, do jakich zadań można wykorzystać narzędzie Airflow oraz co to jest DAG. Przedstawiłem składnię podstawowego DAG-a. W skrócie powiedziałem też, w jaki sposób można postawić Airflowa na swojej maszynie. W tym krótkim artykule poruszyłem kilka tematów, wprowadzających i opowiadających o platformie Airflow. Wiadomo jednak, że najlepiej uczyć się i poznawać technologie, pracując z nią, więc zachęcam do postawienia Airflowa u siebie na komputerze i rozpoczęcia tworzenia DAG-ów. : )
Autor:
Piotr Krajewski – Data Engineer dostarczający rozwiązania Big Data głównie z wykorzystaniem języka Python. W Onwelo pracuje od grudnia 2022 r., działając w projektach, w których wykorzystuje swoją wiedzę, a także poznaje nowe technologie.
* Część zrzutów pochodzi ze strony Apache Airflow, a część widoków jest materiałem własnym autora.
Zostaw komentarz
Polecamy

Sztuczna inteligencja w wykrywaniu zagrożeń bezpieczeństwa IT
Cyberbezpieczeństwo to nie tylko zaawansowane technicznie systemy zabezpieczeń w dużych firmach czy wojsku. To także nasze prywatne bezpieczeństwo, walka z zagrożeniami i ich prewencja w codziennym życiu oraz wiedza o bezpiecznym korzystaniu z internetu. Adam Kowalski-Potok, nasz Seurity Engineer, opowiada jak AI i jej rozwój wpływa na wykrywanie zagrożeń w cyber security.

Budowanie systemów biznesowych z zastosowaniem generatywnej sztucznej inteligencji
Generatywne AI ma potencjał do automatyzacji zadań zajmujących dziś do 70% czasu pracowników. Dlaczego platforma OpenAI nie wystarczy do wykorzystania pełni tych możliwości? Przed nami artykuł Łukasza Cesarskiego i Marka Karwowskiego z Onwelo powstały na bazie prezentacji wygłoszonej podczas konferencji „Transformacje cyfrowe dla biznesu”.

Data & Analytics – architektura systemów jutra
Jaka jest historia inżynierii danych? Jak przebiegał rozwój technologii i na jakie trendy zwraca obecnie uwagę świat? Marek Kozioł, Data Solution Architect i Arkadiusz Zdanowski, Cloud Data Engineer & Team Leader w Onwelo opowiedzieli o tych zagadnieniach podczas konferencji „Transformacje cyfrowe dla biznesu”. Zapraszamy do lektury artykułu przygotowanego na bazie tego wystąpienia.
Sztuczna inteligencja w wykrywaniu zagrożeń bezpieczeństwa IT
Cyberbezpieczeństwo to nie tylko zaawansowane technicznie systemy zabezpieczeń w dużych firmach czy wojsku. To także nasze prywatne bezpieczeństwo, walka z zagrożeniami i ich prewencja w codziennym życiu oraz wiedza o bezpiecznym korzystaniu z internetu. Adam Kowalski-Potok, nasz Seurity Engineer, opowiada jak AI i jej rozwój wpływa na wykrywanie zagrożeń w cyber security.
Budowanie systemów biznesowych z zastosowaniem generatywnej sztucznej inteligencji
Generatywne AI ma potencjał do automatyzacji zadań zajmujących dziś do 70% czasu pracowników. Dlaczego platforma OpenAI nie wystarczy do wykorzystania pełni tych możliwości? Przed nami artykuł Łukasza Cesarskiego i Marka Karwowskiego z Onwelo powstały na bazie prezentacji wygłoszonej podczas konferencji „Transformacje cyfrowe dla biznesu”.