Wyszukiwarki towarzyszą nam w codziennym życiu – szukamy czkających kotów na YouTubie, dmuchanych balonów w kształcie mopsa na AliExpress czy daty premiery nowego sezonu „Gry o Tron” w Google Search. Ta ostatnia jest najbardziej popularną wyszukiwarką internetową posiadającą niemalże osiemdziesiąt procent udziałów w rynku.
Analiza korzystania z silnika Google’a przez użytkowników daje nam podstawowe miary tego, co można uznać za dobrą wyszukiwarkę – zwiększającą produktywność i budzącą zaufanie.
Wskaźniki te mogą nam pomóc w stworzeniu własnej wyszukiwarki, z której chętnie będziemy korzystać. Niekoniecznie będzie ona na skalę Google’a, ale znacznie poprawi doświadczenia użytkowników naszego portalu czy aplikacji.
Czego dowiesz się z artykułu?
1. Co charakteryzuje dobrą wyszukiwarkę?
2. Czego nie robić, implementując wyszukiwarkę w swojej aplikacji?
3. Z jakich technologii skorzystać, budując wyszukiwarkę?
4. Jak wykorzystać machine learning, by poprawić efektywność wyszukiwarki?
5. Jak Onwelo może pomóc Ci w stworzeniu wyszukiwarki idealnej?
Druga strona niemocy
„The best place to hide a body is page 2 of Google Search Results”
Od lat w Internecie krąży powyższy żart i, choć trzeba na niego spojrzeć z przymrużeniem oka, jest to bardzo trafna metafora.
Przeprowadzone przez analityków badania wskazały, że pierwsza strona Search’a odpowiada za dziewięćdziesiąt pięć procent kliknięć. Przy przeciętnej liczbie zapytań dziennie na poziomie 3.5 mld oznacza to, że ponad 3.3 mld razy Google za pierwszym razem „wie”, czego szukamy.
Tym samym mamy pierwszą cechę charakteryzującą dobrą wyszukiwarkę – precyzję. Za każdym razem, gdy pytamy o coś Google Search, dostajemy liczbę rezultatów liczoną w setkach tysięcy, a nawet w milionach. Jak często zdarza Ci się jednak sprawdzić więcej niż cztery czy pięć rezultatów? No właśnie – to dlatego, że wyszukiwarka podpowiada nam bardzo dokładnie.
Wyniki w mgnieniu oka
Wykonując zapytanie w Search’u, poza listą rezultatów i ich przybliżoną liczbą, dostajemy także czas uzyskania odpowiedzi. Statystyki wyszukiwarki Google wskazują, że czas wykonania zapytania to średnio 200 milisekund – szybciej niż pojedyncze mrugnięcie oka.
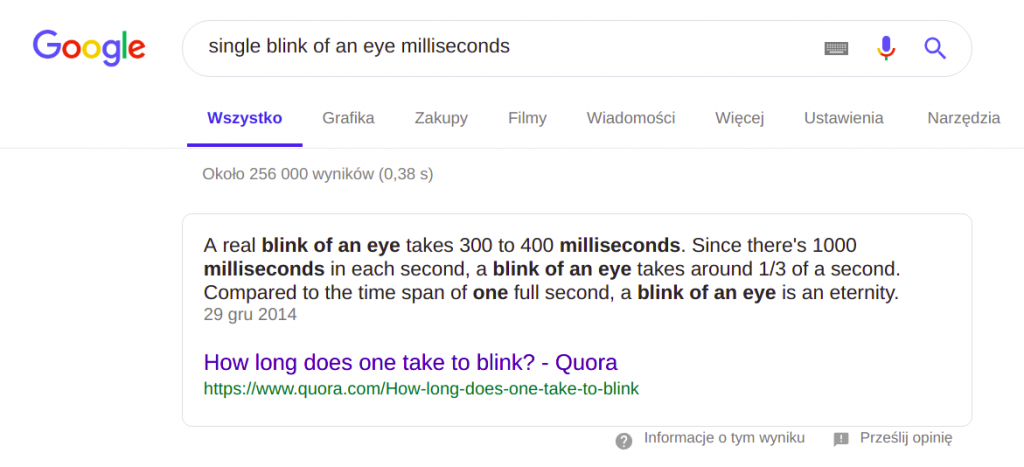
Grafika 1. Informacje dotyczące wykonania zapytania Google Search
Pojawia się więc druga miara dobrej wyszukiwarki – czas odpowiedzi. Nawet największa precyzja nie zrekompensuje nam długiego czasu czekania na odpowiedź – potrzebujemy jej tu i teraz.
Relacyjne bazy danych – dobry pomysł?

Powyższe zapytanie na pewno można by wykorzystać do wyszukiwania, lecz mimo że język SQL jest niezwykle popularny, wykorzystanie relacyjnej bazy danych w roli wyszukiwarki nie jest rekomendowane ze względu na:
- możliwość wyszukiwania tylko dokładnie dopasowanych wyników
- brak oceny dopasowania wyników i zwrócenia w pierwszej kolejności tylko najlepszych
- znikomą elastyczność przy konstrukcji zapytań – brak możliwości dostrajania wyników wyszukiwania
- brak analizy pełnotekstowej przechowywanego tekstu
- obciążanie systemu transakcyjnego niecorowymi funkcjonalnościami
Bazy relacyjne: 👎
Lucene in the sky with diamonds

Naturalnym wyborem przy budowaniu wyszukiwarki jest Elasticsearch – technologia open source wykorzystująca silnik Apache Lucene do wyszukiwania pełnotekstowego (ang. full text search) z ogromnymi możliwościami tuningowania zapytań i analizowania załadowanego tekstu. Na podstawie wykonanego zapytania Elasticsearch zwraca zestaw pasujący rezultatów wraz z oceną tego, jak dobrze dopasowany jest wynik do wystosowanego zapytania.
Dlaczego warto wykorzystać technologie wyszukiwania pełnotekstowego?
- Każdy zwrócony dokument jest opatrzony oceną (ang. score) dopasowania do danego zapytania
- Istnieje możliwość wyszukiwania zarówno dokładnych, jak i częściowych dopasowań (literówki, błędy w danych, fragmenty słów)
- Otrzymujemy szerokie możliwości parametryzacji zapytań – priorytetyzowanie pól, dopasowanie częściowe
- Indeksowany tekst jest domyślnie analizowany (tokenizacja, stemming) przez silnik wyszukiwania
Najciekawsze funkcjonalności full text search w Elasticsearch
Fuzzy search – zapytanie bierze poprawkę na wszelkiego rodzaju literówki (czy to w danych czy w zapytaniu) i nie pomija takich dokumentów w zwracanym wyniku. Wyżej oceniane są dopasowania idealne, ale te mniej dokładne także znajdą się w zwróconych rezultatach.
Multi-match – często informacja, której szuka użytkownik może być w więcej niż w jednym polu. W takich sytuacjach możemy wykorzystać zapytanie typu multi-match, by wskazać, w których polach mamy szukać danej frazy (można używać także wildcardów na wspólny fragment nazw atrybutów).
Zapytanie multi-match:
- wykona osobne podzapytanie (zapytanie typu match) dla każdego z pól w sekcji fields
- obliczy score dla każdego z wykonanych podzapytań
- wyliczy score dokumentu jako sumę wartości score wykonanych podzapytań (most_fields) lub jako maksimum z tych wartości (best_field)
Query-time boosting – jest to mechanizm wykorzystywany w zapytaniach typu multi-match do ustalenia, które pole jest dla nas ważniejsze. Zdefiniowanie różnych wag dla poszczególnych pól w zapytaniu wpłynie na kalkulację wartości score dla każdego z dokumentów – im wyższa waga danego pola, tym wyższy score dokumentu zawierającego szukaną frazę w tym polu.
Highlighting – w otrzymanych wynikach możemy umieścić także rezultat z tagami HTML okalającymi fragment tekstu, który przyczynił się do uwzględnienia danego dokumentu w wynikach. Funkcjonalność idealna do wzbogacenia interfejsu aplikacji webowych.
Elasticsearch: 👍
Elasticsearch + machine learning = wyszukiwarka na sterydach 💪
Już samo zaindeksowanie surowych danych bez uprzedniego preprocessingu sprawdzi się w znacznej liczbie przypadków dużo lepiej niż odpytywanie bazy relacyjnej. Żyjemy jednak w czasach, w których hodujemy rośliny na księżycu, a Ubera zamawia nam wirtualny asystent. W kwestii wyszukiwania też da się wejść na wyższy poziom.
W poprawie precyzji wyszukiwarki możemy wykorzystać osiągnięcia nauki w zakresie uczenia maszynowego (ang. machine learning) w dziedzinie NLP (Natural Language Processing). Największe z nich dotyczą języka angielskiego, który jest najczęściej wykorzystywanym językiem na świecie i jednym z najłatwiejszych do analizy. To właśnie dokumenty w tym języku będą używane przeze mnie w celach demonstracyjnych.
Pierwszym zagadnieniem NLP, które będzie pomocne przy rozwijaniu wyszukiwarki, jest NER, czyli Named-Entity Recognition. Jest to zadanie ekstrakcji informacji z tekstu (artykułu, dokumentu, relacji, fragmentu książki, etc.). Poszukujemy wartości konkretnych encji, czyli reprezentacji danych obiektów przynależnych do danej kategorii. Kategoria to np. miejsce, osoba, a encja tej kategorii to odpowiednio: Warszawa, Ronnie O’Sullivan.
Drugie z nich polega na ustaleniu kategorii dokumentu ze względu na treść (słowa zawarte w dokumencie, ich kolejność, częstotliwość, etc.). W zależności od wybranego algorytmu możemy dokonywać:
- klasyfikacji dokumentów – poprzez ocenę prawdopodobieństwa przynależności dokumentu do danej kategorii (uprzednio zdefiniowanych w procesie uczenia modelu)
- klasteryzacji dokumentów – polegającej na łączeniu najbardziej podobnych dokumentów razem w grupy (klastry). W tym wypadku to do nas należy definicja kategorii danego klastra już po ich utworzeniu
Przykładami kategorii mogą być: sztuka, sport, wiadomości, technologia.
Preprocessing = We ❤ Cloud
Odpowiednio obsłużony proces przetwarzania dokumentów (z wykorzystaniem machine learningu) oraz załadowanie ich do indeksu Elasticsearch umożliwi nam zbudowanie precyzyjnej, inteligentnej i szeroko parametryzowalnej wyszukiwarki. Do tego celu możemy wykorzystać gotowe modele machine learning dostępne w Google Cloud Platform Natural Language API.
Usługa ta umożliwia między innymi:
- przeprowadzanie analiz typu NER – rozpoznawanie w dokumencie encji wraz z oceną istotności każdej encji w danym dokumencie (ang. salience)
- klasyfikację dokumentów – przypisanie dokumentowi jednej lub wielu kategorii z oceną prawdopodobieństwa przynależności do tej kategorii
- analizę sentymentu – polegającą na ocenie nacechowania emocjonalnego (pozytywne / neutralne / negatywne) dokumentu
Języki obsługiwane w ramach tej usługi to: angielski, hiszpański, japoński, chiński, francuski, niemiecki, włoski, koreański oraz portugalski.
Showtime 🔥
Na potrzeby demonstracji możliwości Elasticsearch załadowałem do indeksu o odpowiednio skonfigurowanym mappingiem ~1,000 artykułów z agencji Reuters (lata 1994-1995) preprocessowanych z wykorzystaniem Natural Language API.

Grafika 2. Zapytanie 1 oraz 2
Wyszukiwanie po treści dokumentu
W pierwszym kroku będziemy szukać artykułów dotyczących Japonii, wykorzystując wyłącznie surowy tekst artykułu (pole text), używając zapytania nr 1.
| Score | Tytuł artykułu | Pola zawierające szukany tekst |
|---|---|---|
| 4.61 | JAPAN MINISTRY HAS NO COMMENT ON RICE TALKS REPORT | text, entitles.location.low |
| 4.53 | Bank of Japan intervening to support dollar against yen, dealers | text, entities.organization.very_high |
| 4.50 | BANK OF JAPAN INTERVENES TO BUY DOLLARS AROUND 143.70 YEN – DEALERS | text, entities.organization.low |
| 4.50 | Bank of Japan intervenes to support dollar after Tokyo opening, dealers | text, entities.organization.medium |
| 4.49 | JAPAN BUYS 5,000 TONNES CANADIAN RAPESEED | text, entities.organization.medium |
Tabela 1. Top 5 rezultatów – posortowane po wartości score (zapytanie nr 1)
Wyszukiwania po treści dokumentu i rozpoznanych encjach
Teraz spróbujemy czegoś bardziej zaawansowanego. Zapytanie nr 2 wykorzystuje mechanizm multi-match, w którym, poza polem text uwzględnimy także encje rozpoznane przez algorytmy machine learning. Każdy z typów encji przechowuje rozpoznane obiekty w osobnym atrybucie, w zależności od oceny istotności (salience). Przykładowo encje typu Person przechowywane są w pięciu atrybutach: entities.person.split.{very_low, low, medium, high, very_high}.
Wykonane zapytanie faworyzowało dokumenty, dla których odnaleziona encja ma wyższą ocenę istotności – im jest ona wyższa, tym wyższy score dokumentu w rezultatach.
| Score | Tytuł artykułu | Pola zawierające szukany tekst |
|---|---|---|
| 78.46 | JAPAN MINISTRY SAYS OPEN FARM TRAD WOULD HIT U.S. | entities.organization.low, text, entities.location.very_high |
| 40.83 | JAPAN BUYS 5,000 TONNES CANADIAN RAPESEED | text, entities.organization.medium |
| 40.82 | Japan March wholesale prices rise 0.2 pct | text, entities.organization.medium |
| 40.77 | JAPAN BUYS 4,000 TONNES CANADIAN RAPESEED | entities.organization.medium |
| 40.66 | Bank of Japan intervening to support dollar against yen, dealers | entities.organization.very_high |
Tabela 2. Top 5 rezultatów – posortowane po wartości score (zapytanie nr 2)
Po wartości score widać, że zapytanie faworyzuje dokumenty zawierające szukaną frazę w polach o wyższej istotności.
Porównanie rozkładu score w wykonanych zapytaniach
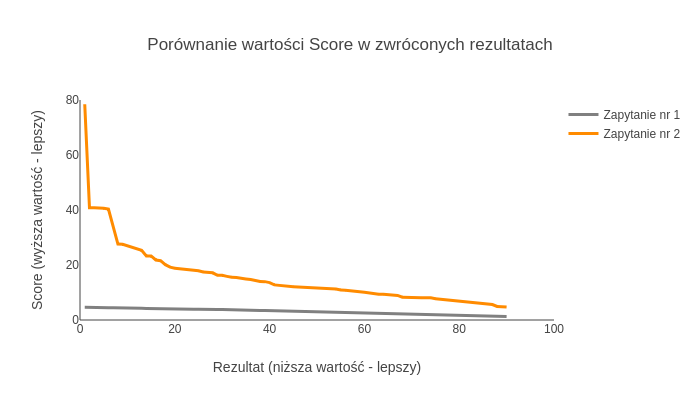
Grafika 3. Porównanie wartości score w zwróconych rezultatach
Zapytanie nr 1 dało nam stosunkowo jednostajne wyniki – różnice między ocenami kolejnych dokumentów są niewielkie. Score dwudziestego rezultatu jest niższy od score’u pierwszego o ~13%. Ze względu na taką charakterystykę rozkładu ocen trudniej nam określić, czy szukany dokument znajduje się na pierwszej stronie wyników wyszukiwania.
W przypadku zapytania nr 2 jednostajność pojawia się w okolicach dwudziestego rezultatu. Jego score jest niższy od score’u pierwszego ponad czterokrotnie i dopiero od tego momentu różnice między kolejnymi rezultatami stopniowo maleją. Udało nam się odnaleźć lepsze dopasowania i bardziej wyraźnie odseparować je od wszystkich dokumentów spełniających kryteria wyszukiwania – użytkownik rzadziej będzie potrzebował zaglądać na drugą stronę wyników.
Jeśli chodzi o czas wykonania zapytań, to w obu przypadkach osiągnięte zostały wyniki poniżej 200 milisekund – zwiększanie precyzji nie pociągnęło za sobą utraty pożądanej wydajności.
Poprawa wyników jest widoczna gołym okiem – warto skorzystać z procesu preprocessingu, by wejść ze swoją wyszukiwarką na wyższy poziom.
Enterprise Search w Onwelo
W Onwelo, w ramach usług z zakresu Business Intelligence, proponujemy klientom rozwiązania typu Enterprise Search, w których łączymy dane z różnych źródeł (bazy relacyjne, systemy CRM, data lake) i w różnych formatach (dokumenty tekstowe, zdjęcia) w jeden indeks na potrzeby realizacji precyzyjnego i szybkiego wyszukiwania uwzględniającego tzw. 360° Single View – jedno repozytorium dające nam możliwość przeszukiwania wszystkich typów mediów dostępnych w przedsiębiorstwie.
Grafika 4. Enterprise Search łączący wszystkie dane w przedsiębiorstwie w 360° Single View
Mariusz Górski – niestrudzony fanatyk nowoczesnych technologii Big Data i rozwiązań open source. W Onwelo wdraża rozwiązania oparte m.in. na stacku Elastic (Elasticsearch, Logstash, Kibana, Beats) oraz Apache Hadoop (w tym Spark, Kafka). Programuje przede wszystkim w Pythonie. Po godzinach ogląda Snookera i popija kawę czarną jak terminal.
Podobał Ci się ten wpis? Sprawdź inne artykuły z obszaru Business Intelligence!
Zostaw komentarz
Polecamy

Sztuczna inteligencja w wykrywaniu zagrożeń bezpieczeństwa IT
Cyberbezpieczeństwo to nie tylko zaawansowane technicznie systemy zabezpieczeń w dużych firmach czy wojsku. To także nasze prywatne bezpieczeństwo, walka z zagrożeniami i ich prewencja w codziennym życiu oraz wiedza o bezpiecznym korzystaniu z internetu. Adam Kowalski-Potok, nasz Seurity Engineer, opowiada jak AI i jej rozwój wpływa na wykrywanie zagrożeń w cyber security.

Budowanie systemów biznesowych z zastosowaniem generatywnej sztucznej inteligencji
Generatywne AI ma potencjał do automatyzacji zadań zajmujących dziś do 70% czasu pracowników. Dlaczego platforma OpenAI nie wystarczy do wykorzystania pełni tych możliwości? Przed nami artykuł Łukasza Cesarskiego i Marka Karwowskiego z Onwelo powstały na bazie prezentacji wygłoszonej podczas konferencji „Transformacje cyfrowe dla biznesu”.

Data & Analytics – architektura systemów jutra
Jaka jest historia inżynierii danych? Jak przebiegał rozwój technologii i na jakie trendy zwraca obecnie uwagę świat? Marek Kozioł, Data Solution Architect i Arkadiusz Zdanowski, Cloud Data Engineer & Team Leader w Onwelo opowiedzieli o tych zagadnieniach podczas konferencji „Transformacje cyfrowe dla biznesu”. Zapraszamy do lektury artykułu przygotowanego na bazie tego wystąpienia.
Sztuczna inteligencja w wykrywaniu zagrożeń bezpieczeństwa IT
Cyberbezpieczeństwo to nie tylko zaawansowane technicznie systemy zabezpieczeń w dużych firmach czy wojsku. To także nasze prywatne bezpieczeństwo, walka z zagrożeniami i ich prewencja w codziennym życiu oraz wiedza o bezpiecznym korzystaniu z internetu. Adam Kowalski-Potok, nasz Seurity Engineer, opowiada jak AI i jej rozwój wpływa na wykrywanie zagrożeń w cyber security.
Budowanie systemów biznesowych z zastosowaniem generatywnej sztucznej inteligencji
Generatywne AI ma potencjał do automatyzacji zadań zajmujących dziś do 70% czasu pracowników. Dlaczego platforma OpenAI nie wystarczy do wykorzystania pełni tych możliwości? Przed nami artykuł Łukasza Cesarskiego i Marka Karwowskiego z Onwelo powstały na bazie prezentacji wygłoszonej podczas konferencji „Transformacje cyfrowe dla biznesu”.